1. 标题
· Deep Multiple Instance Convolutional Neural Networks for Learning Robust Scene Representations
· 多示例深度卷积神经网络图像场景表达
2. 成果信息
Zhili Li, Kai Xu, Jiafen Xie, Qi Bi, and Kun Qin. Deep Multiple Instance Convolutional Neural Networks for Learning Robust Scene Representations. IEEE Transactions on Geoscience and Remote Sensing.
DOI: 10.1109/TGRS.2019.2960889
该研究由国家自然科学基金(41801265),国家重点研发计划(2016YFB0502603)联合资助;
3. 成果团队成员
许凯(通讯作者),博士,bat365官网登录入口,讲师,主要研究方向为深度学习遥感图像目标检测和识别。
李智立,硕士研究生,bat365官网登录入口
解加粉,硕士研究生,bat365官网登录入口
毕奇,硕士研究生,武汉大学遥感我院
秦昆,教授,武汉大学遥感我院
4. 成果介绍
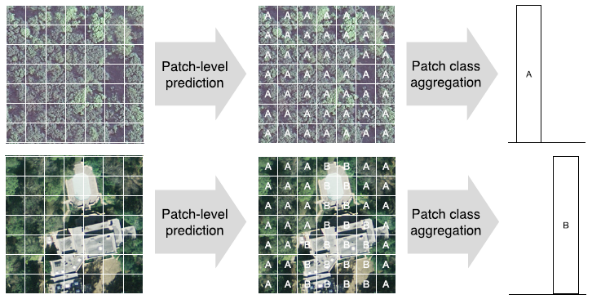
遥感图像场景通常由多种地物目标组成,场景中的局部语义表现出不一致性,语义对场景识别的贡献也是不同的。尤其是场景中的小目标,容易受到频繁出现的背景干扰,使得深度卷积神经网络全局特征更多地关注于背景,强化背景对场景标签的贡献,因而很难准确表达场景中的小目标。
我们将图像场景分裂成若干重叠视窗,提取视窗的中层卷积特征为示例特征(犹如手持放大镜搜寻目标),则图像场景被表达为多示例的集合。示例分类器将视窗转换为语义特征,局部语义对全局标签的贡献程度被注意力机制所度量和评价,示例汇集函数将上下文语义特征融合为场景标签,从而实现局部低层语义特征向场景高层语义标签的转换。
上述过程形成一个端到端的网络架构,架构中的卷积神经网络模型可由AlexNet、VGG、ResNet等填充。为了避免过分关注于小目标,多尺度空洞卷积被用来扩大网络模型的感受野,以适应不同尺度的目标。
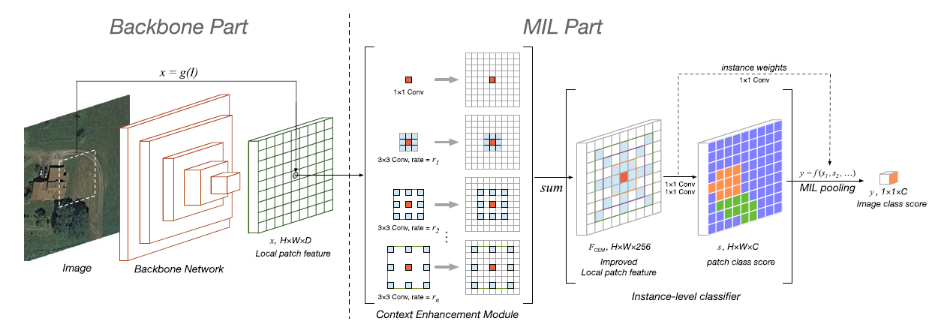
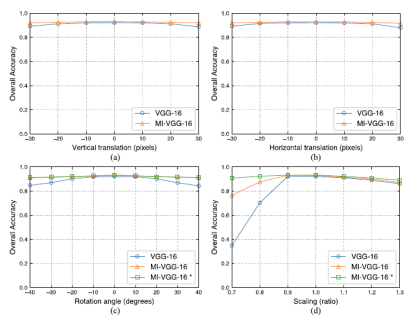
算法在平移、旋转,尤其是缩放变换中表现出了鲁棒性,感受野可随目标尺度变化而自适应缩放。在UCM、AID和NWPU数据集中,以网络参数数量减少约1个数量级的情况下,比传统网络模型取得了更高的分类精度。

在无人区中,能忽略沙漠和植被等背景干扰,发现场景中的建筑物小目标。





