1. 标题
· Reconstructed Similarity for Faster GANs-Based Word Translation to Mitigate Hubness
· 一种有效缓解神经机器翻译模型中枢纽问题的算法
2. 成果信息
· 论文、专著、专利、软件、奖项、新闻报道的完整信息,务必使用规范的引用格式
o Dejun Zhang, Mengting Luo, Fazhi He. Reconstructed Similarity for Faster GANs-Based Word Translation to Mitigate Hubness. Neurocomputing, 2019, 362: 83-93.
· URL: https://linkinghub.elsevier.com/retrieve/pii/S0925231219309968
· DOI: https://doi.org/10.1016/j.neucom.2019.06.082
· CODE: https://github.com/djzgroup/RSforWordTranslation
· This work was supported in part by the National Natural Science Foundation of China under Grant 61702350.
3. 成果团队成员
· 张德军(第一作者,通讯作者),讲师,bat365官网登录入口。研究方向:三维场景理解、人体姿态估计、目标跟踪与识别、自然语言处理。
Email: zhangdejun@cug.edu.cn
· 罗梦婷,本科生,四川大学视觉合成图形图像技术国防重点学科实验室。研究方向:神经机器翻译。
· 何发智,教授,武汉大学计算机学院。研究方向:计算机图形学、计算机辅助设计、视频分析与理解、自然语言处理。
4. 成果介绍
在神经机器翻译中,最近邻检索能够从统一的多语言语义特征空间中检索最佳的翻译候选词作为源查询的语言标签。众所周知,高维特征空间中的枢纽(在高维空间中,一部分测试集的类别可能会成为很多数据点的最近邻点,但其类别之间却没什么关系)严重影响了最近邻检索。目前主流算法大都采用排除候选翻译列表中的枢纽,以缓解此问题。然而,枢纽也有对应的翻译,排除枢纽的算法有很大的缺陷。
本研究提出一种有效缓解神经机器翻译模型中枢纽问题的算法(图1所示),解决了密集空间和高维空间中的枢纽度问题,使得枢纽与翻译候选词具有等概率分布,从而避免了枢纽被不恰当地排除掉。重构相似性通过度量每个源查询嵌入的双语种距离和单语种距离的双边相似性来提高双语词典的质量。此外,为了构建无监督的神经机器翻译模型,本研究引入了生成对抗网络,将源语言单词的分布和目标语言单词的分布映射到共享的语义空间中,并构建了一个微小的生成对抗网络拓扑网络。为了进一步对齐跨语言的词嵌入分布,本研究还采用了正交普氏映射、全局感知的变换矩阵和目标语言空间尺度缩放,以提供灵活且可选的多重优化。
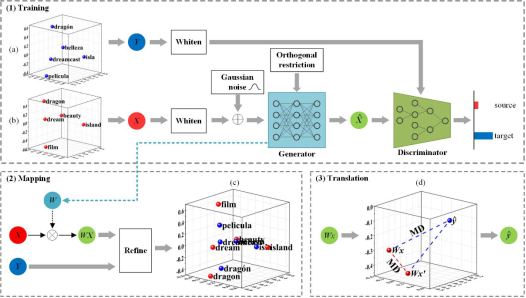
图1 一种有效缓解神经机器翻译模型中枢纽问题的算法
(1)训练过程
a和b分别表示在特征空间中经过预训练的源语言和目标语言的词嵌入。红色和蓝色词嵌入的分布是相对独立的。首先,将源语言的词嵌入和目标语言的词嵌入白化,并在源语言的词嵌入中加入乘性高斯噪声。然后,训练生成器以最小化输出与目标语言词嵌入之间的误差。然后,利用空间正交约束生成器的参数。最后,训练判别器从目标分布中判断出变换后的源嵌入。交替进行以上两步训练过程,直至算法收敛。
(2)线性映射过程
利用正交变换将源语言分布与目标语言分布在空间中对齐。如图1中c所示,大多数单词对都大致对齐到共享的语义特征空间中。此外,本研究提供了三种可选项(正交普氏映射、全局感知变换矩阵和目标语言空间尺度缩放)来进一步微调正交变换。
(3)翻译过程
通过重构相似性(同时考虑了双语种距离和单语种距离)从映射之后的词嵌入空间d中检索源语言单词的最佳K个目标语言的候选词。
论文的实验环节还包括了算法收敛分析、双语词典抽取、跨语言语义相似度分析、超参数分解实验和可视化结果。
代码网址:https://github.com/djzgroup/RSforWordTranslation
本研究在没有任何跨语言信息的情况下,在英语-意大利语和英语-芬兰语翻译任务上获得了最新的成果(分别提升近2%和4%)。与基于GAN的模型相比,本研究可在最短的时间内获得较好的结果,在速度和精度之间取得良好的平衡。
· 创新点
(1)首次提出结合双语种距离和单语种距离的重构相似性,用于评估候选词的似然率。首次提出整合全局权重和局部权重的全局感知变换矩阵。在统一的特征空间中,以重构相似性为度量准则,选择最佳K个目标语言的候选词,在不排除枢纽的前提下有效缓解了枢纽污染问题。
(2)提出一种无监督的翻译模型,在双语词典抽取任务中获得了最好的效果;在英语翻译成芬兰语的任务中,即使没有单个平行语料库的情况下明显超越了现有的监督模型。显著缩短了神经机器翻译模型的训练时间,单个CPU只需要几分钟时间,比NIPS 2018最新论文快了将近52到105倍。



